What are Managed Cloud Services? A 2025+ Guide to Outcomes, Not Outsourcing
Managed cloud services have evolved far beyond simple IT outsourcing. In 2025, a managed service is a strategic partnership where a third-party expert takes full responsibility for your cloud infrastructure, operations, and, most importantly, business outcomes.
This frees your internal team from the daily grind of maintenance, security patching, and performance tuning, letting them focus on what they do best: building great products and driving innovation.
Redefining Managed Services as Outcome-as-a-Service

The old-school view of managed services as basic IT outsourcing is completely outdated. The highest-ROI managed services in 2025 are those that guarantee business outcomes via contractual SLAs backed by financial penalties. We call this new model Outcome-as-a-Service.
This is more than just a fancy new term—it’s a fundamental change in how value is delivered. Instead of paying a provider to simply keep the systems running, you’re securing specific, contract-bound promises for performance, availability, and cost.
The New Standard for Cloud Value
Let’s make this real. Stop buying “managed Kubernetes” and start buying “managed 5-ms global read latency for your product catalog.” See the difference? This approach directly ties your technology spending to tangible business goals, like a lightning-fast user experience or seamless e-commerce transactions.
The major cloud providers are all-in on this model, baking outcome-based guarantees into their top-tier services. For instance:
- Azure Cosmos DB offers an impressive 99.999% availability SLA.
- Google Cloud Spanner delivers rock-solid guarantees for global transactional consistency.
- Amazon Aurora Global Database provides predictable, low-latency reads across multiple continents.
With these services, the burden of managing complex operations like multi-region failover, latency optimization, and security is entirely on the provider. Your team simply consumes the outcome—high availability and speed—without getting bogged down in the complex mechanics. This strategic shift is a critical concept for anyone looking to compare cloud service providers and get the most out of their investment.
Managed Services Evolution From Outsourcing to Outcomes
The journey from a task-based model to an outcome-driven one represents a significant evolution in the value proposition of managed services. The table below breaks down the key differences between the traditional and modern approaches.
| Attribute | Traditional Outsourcing Model | Modern Outcome-as-a-Service Model |
|---|---|---|
| Primary Focus | Task completion (e.g., patching, backups) | Business results (e.g., 99.99% uptime, <50ms latency) |
| Key Metrics | Activities completed, tickets closed | Uptime, latency, transaction cost, speed |
| Provider Role | Order-taker, hands-on support | Strategic partner, outcome guarantor |
| Value Proposition | Cost reduction, staff augmentation | Risk reduction, business acceleration, cost predictability |
| Contracts | Based on labor hours or managed devices | Based on guaranteed SLAs with financial penalties |
This transition highlights why modern managed services are so much more than just “IT for hire.” They have become a key ingredient for achieving and maintaining a competitive edge.
A Market Driven by Measurable Results
This move from a reactive, break-fix mentality to a proactive, results-focused partnership is what’s driving the massive growth in the market. In 2025, the cloud managed services market hit an estimated USD 155.73 billion. Projections show that figure soaring to an anticipated USD 482.93 billion by 2034, a clear sign that enterprises are voting with their budgets for reliable, outcome-driven cloud management. You can dive into the data behind these projections over at Precedence Research.
The core idea of Outcome-as-a-Service is simple: Pay for the result, not the effort. This model aligns the provider’s success directly with your business objectives, creating a true partnership built on performance, security, and measurable value.
Ultimately, understanding managed cloud services today means grasping this critical distinction. It’s not about offloading work; it’s about buying operational excellence and guaranteed performance to push your business forward.
The Fastest Path to Day-Two Operational Excellence

One of the biggest benefits of managed cloud services is instant access to elite operational reliability. Internal teams take 9–18 months to reach the reliability of a hyperscaler’s managed offering that has already absorbed 10+ years of attacks and failures.
Think about it. Services like Amazon DynamoDB or Google Cloud Spanner aren’t just pieces of software. They are battle-hardened systems that have endured more than a decade of real-world attacks, outages, and strange failure scenarios. When you adopt them, you’re inheriting all that operational wisdom on day one.
You get to skip the painful learning curve. This shortcut to what we call “day-two excellence” is a massive competitive advantage, freeing up your engineers to innovate instead of constantly reinventing the wheel.
The Hidden Costs of Self-Management
When you look at the total cost of ownership (TCO) for doing it yourself, the server bill is just the tip of the iceberg. The real drain on your budget is the immense engineering effort needed for routine maintenance, late-night emergencies, and complex system administration.
Let’s take a common example: deciding between running a self-managed Cassandra cluster and using a fully managed NoSQL database like DynamoDB or ScyllaDB Cloud. On paper, the raw infrastructure costs might look similar at first glance. But a closer look tells a very different story.
Factor in the engineering hours spent on incident response, painful version upgrades, and constant anti-entropy repairs, and a self-managed Cassandra instance in 2025 costs 4 to 7 times more than its fully managed equivalent.
This cost gap reveals a critical truth: your most valuable and expensive resource is your engineering team. Managed services let you point that talent away from operational chores and toward building features that actually make you money. For companies navigating a digital transformation, this is a core principle of successful cloud adoption, a topic we explore further in our guide to AWS migration best practices.
Comparing Self-Managed vs Managed Database TCO
The cost difference becomes crystal clear when you break down where your team’s time actually goes. This table illustrates the operational overhead for each approach, showing exactly why managed services deliver such a strong return on investment.
| Operational Task | Self-Managed Cassandra (Per Month) | Managed DynamoDB / ScyllaDB Cloud |
|---|---|---|
| Incident Response | 15-30 engineer hours | Handled by provider; included in service cost |
| Software Upgrades | 10-20 engineer hours per quarter | Zero engineer hours; seamless and automatic |
| Anti-Entropy Repairs | 5-10 engineer hours | Handled by provider; built into the service |
| Security Patching | 5 engineer hours | Zero engineer hours; handled by provider |
| Capacity Planning | 8 engineer hours | Automated or simple configuration |
| Backup & Recovery | 4 engineer hours | Automated with point-in-time recovery |
This breakdown shows how managed services fundamentally shift your cost structure. You’re not just buying infrastructure; you’re buying back thousands of hours of your best people’s time, letting them focus on what truly drives the business forward.
The 60/30/10 Rule: A Practical Framework for Workload Tiering
The smartest cloud strategies are all about ruthless prioritization. One of the most effective models for this is the 60/30/10 Rule, a disciplined approach to deciding where your applications live to maximize operational leverage.
Enterprises that enforced this framework in 2024–2025 cut operational toil by 65% and reallocated 40+ engineers to product work. With worldwide public cloud spending expected to hit roughly $723.4 billion in 2025 (up from $595.7 billion the year before, according to cloud computing statistics and insights on CloudZero.com), this rule ensures your cloud spend delivers a real return.
The 60% Core: Fully Managed Services
The rule pushes you to run 60% of your workloads—all the common, undifferentiated heavy lifting—on fully managed services. These are the “commodity” components that keep your business running but don’t define what makes you special.
- Databases: Instead of managing your own database clusters, use services like Amazon RDS, Google Cloud SQL, or Azure SQL. Let the provider worry about patching, backups, and failover.
- Caching Layers: Why build and maintain your own Redis or Memcached clusters? Offload it to Amazon ElastiCache or Google Memorystore.
- NoSQL Data Stores: Go with something like Firestore or DynamoDB that scales massively with almost zero administration from your team.
When you place the bulk of your infrastructure here, you’re not just buying a service; you’re inheriting the provider’s operational excellence on day one. Entire categories of engineering busywork just disappear.
The 30% Balance: Lightly Managed Containers
The next slice, about 30% of your workloads, is for applications that need custom configuration but where you don’t need to control the bare metal. This is the sweet spot for containerized applications running on lightly managed platforms.
Services like Amazon EKS, Azure AKS, or Google GKE are perfect for this tier. They manage the underlying control plane, which is often the most complex part of running Kubernetes. Your team owns the container images and application logic, but the headache of orchestrating the cluster itself is handled by the provider.
The 10% Exception: Self-Managed Infrastructure
Finally, we have the smallest and most heavily scrutinized tier: the 10% reserved for self-managed systems. This category should be treated as a true exception, not the default. A workload should only land here if it meets one of two very strict criteria:
- It contains unique IP: The technology gives you a significant, defensible competitive advantage that can’t be replicated with an off-the-shelf managed service.
- It’s bound by unique regulatory constraints: Some specific data sovereignty or compliance rules might dictate physical hardware control that managed services cannot meet.
By forcing every new service to justify its existence outside the 60% and 30% tiers, you create a powerful default-to-managed culture. This simple but effective governance model is key to accelerating feature velocity and focusing engineering talent on what truly matters.
The Rise of Control-Plane-as-a-Service
What if you could get all the power of modern container orchestration without ever seeing a node? That’s the promise of an even more efficient model: Control-Plane-as-a-Service (CPaaS).
Platforms like Google Cloud Run, AWS App Runner, and Azure Container Apps are at the forefront of this shift. They offer full Kubernetes API compatibility but completely hide the messy infrastructure underneath. Your team just pushes code, and the platform handles everything else—provisioning, networking, and scaling all happen automatically.
The “Zero-Ops” Reality
The impact of a CPaaS model is immediate. Your engineers stop spending their days wrestling with cluster configurations, managing node pools, or worrying about OS patching. This is the “zero-ops” experience, and it’s a huge deal for both development speed and your bottom line.
A few things make these platforms stand out:
- Sub-second cold starts: Applications can spin up from zero to handle a request in under a second.
- Per-request billing: You are billed only for the exact compute resources used to process a request, eliminating costs for idle capacity.
- A dream for developers: Engineers can deploy containers without needing a Ph.D. in infrastructure. The complexity is just gone.
This approach strips away the last frustrating layers of operational overhead, freeing up your team to build features that matter to the business.
We often recommend a “60/30/10” framework for deciding which workloads belong where. The idea is to push as much as possible to fully managed services to maximize your team’s impact.
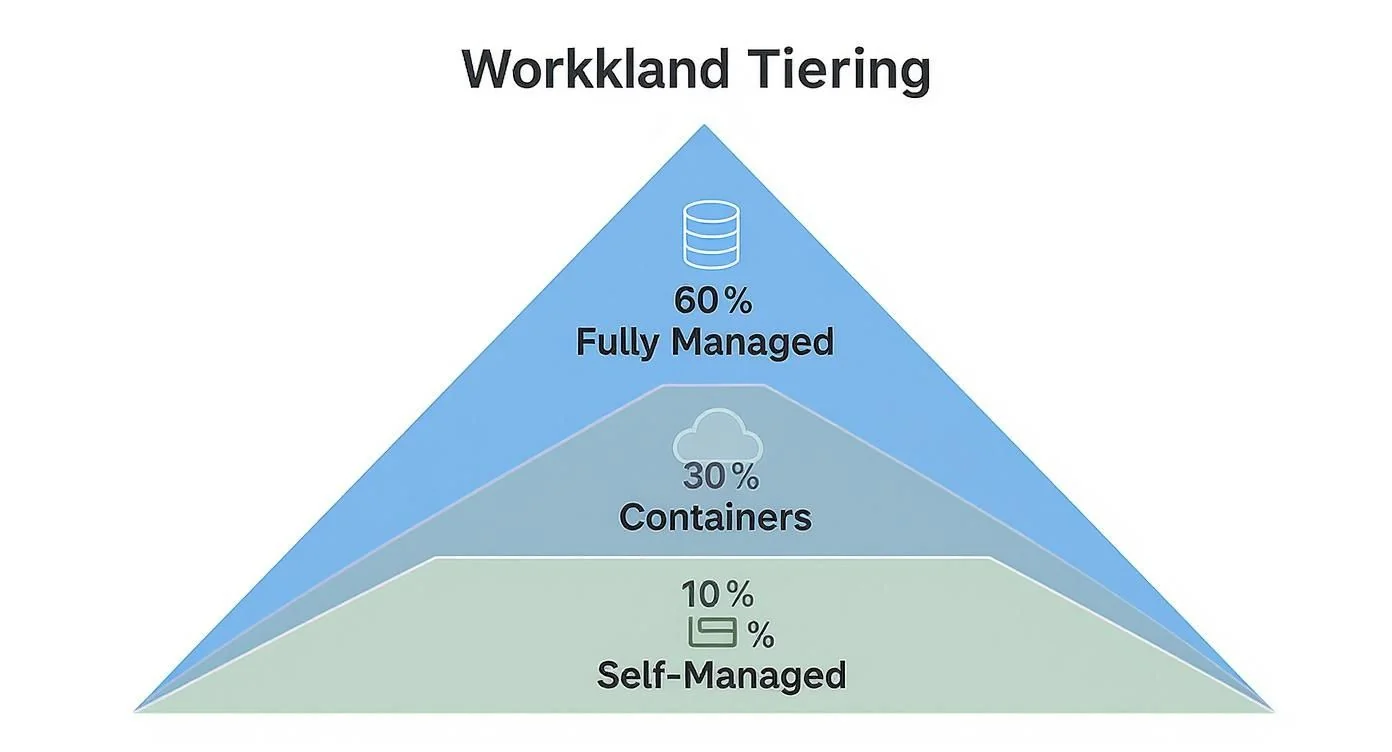
As the pyramid shows, a disciplined strategy dedicates the majority of workloads to fully managed services. This is where you gain the most operational leverage and free up your most valuable engineering talent for innovation.
Rethinking Cost Efficiency
The financial case for Control-Plane-as-a-Service is rock-solid, especially for standard web applications and APIs. When you stop paying for idle compute capacity sitting inside a Kubernetes cluster, the savings add up fast.
Real-world benchmarks from 2025 paint a clear picture. For web-tier workloads handling under 50,000 requests per second, CPaaS platforms are 70–90% cheaper than running the same application on a traditional managed Kubernetes service like Amazon EKS or Google GKE.
This isn’t just about shaving a few percentage points off your cloud bill; it’s a fundamental shift in cost structure. For any organization trying to get the most out of its cloud budget, adopting these zero-ops platforms for the right workloads is one of the smartest financial moves you can make.
Reducing Your Security and Compliance Headaches
One of the most powerful benefits of managed cloud services is leveraging the shared responsibility model to lift the immense weight of security and compliance off your team’s shoulders. Anyone who’s been through a PCI-DSS, HIPAA, or SOC 2 audit knows the resource drain involved.
When you use a managed service like Amazon RDS, Azure SQL, or Google Cloud AlloyDB, the provider takes on 100% of the responsibility for securing the physical data centers, servers, and virtualization layer. Your auditors accept their attestations and certifications for that part of the stack, no questions asked.
This dramatically shrinks your compliance scope. You no longer have to prove that a database server is in a locked cage or that the OS has the latest security patch. You focus on what matters: securing your application and the data that runs on it.
What Used to Take Six Weeks Now Takes Three Days
The difference this makes during an audit is night and day. Teams that moved regulated workloads to managed DBs in 2025 cut compliance audit prep from 6 weeks to 3 days. Instead of a month-plus of pure administrative pain, they simply handed over the provider’s compliance reports for a huge chunk of the audit.
This isn’t magic; it’s just good business for the cloud providers. They’ve already invested millions in getting and maintaining every certification imaginable. It’s a core part of their product. When you sign up, you get to piggyback on that massive, ongoing investment instantly.
Shifting the infrastructure compliance burden frees up your security and engineering experts to do what they do best: threat modeling your application and protecting customer data, not ticking boxes on an infrastructure checklist.
The Market is Voting for Secure, Managed Services
This move toward offloading security and compliance is a huge reason the market is exploding. The managed database services market alone was valued at an estimated USD 445 billion in 2025 and is projected to hit USD 1.5 trillion by 2035. That growth is being driven by companies that need to manage data securely and efficiently while navigating complex rules like GDPR. You can dig into more of the numbers behind this trend over at Future Market Insights.
Of course, not all providers are created equal. When you’re picking a partner, their security and compliance credentials should be at the top of your list. Using a structured approach, like this vendor due diligence checklist, is the best way to make sure a provider can actually meet your specific regulatory needs before you sign on the dotted line.
At the end of the day, using managed services for your regulated workloads is a strategic trade-off. You give up some low-level control over the infrastructure, but you gain tremendous speed, security, and peace of mind.
Building a Managed-First Culture for Lasting Impact
Knowing what managed cloud services are is one thing. Actually changing how your organization operates is where the real value gets unlocked. The goal is to weave a “managed-first” philosophy into your company’s DNA.
This kind of cultural shift is powerful. It stops your teams from constantly reinventing the wheel and frees up your best engineers to focus on what actually moves the needle for your business. Lasting change comes from building systems that make the smart choice the easy choice.
Implement a Managed-First Review Gate
The most effective way to drive this change is to build a formal checkpoint into your development process. Implement a Managed-First Review Gate as a mandatory step in your Architecture Decision Record (ADR) process.
The rule is simple: before any team gets approval for a new service, they must justify why it cannot use an existing managed equivalent. This simple change completely flips the default behavior. Instead of reflexively building something custom, your teams are now forced to start by asking, “Can we use a battle-tested, scalable, and secure managed service for this?”
The results are dramatic. Companies that added this gate in 2025 reduced new custom infrastructure code by 80% and accelerated feature velocity 2.5x.
Plan Your Exit Strategy From Day One
Managed services give you an incredible speed boost, but you have to be careful they don’t become golden handcuffs. The organizations winning in 2025+ treat managed services as accelerators, not handcuffs. They use them for speed today while simultaneously keeping their data egress paths open.
This isn’t about being cynical; it’s about maintaining strategic leverage.
- Stick to Open Data Formats: When building data lakes, use formats like Apache Parquet or Iceberg. This keeps your data portable between services like BigQuery, Redshift, or Snowflake.
- Keep Your Egress Paths Clear: Regularly test and document what it takes to shift a petabyte of data between cloud object stores, like from AWS S3 to Google Cloud Storage or Azure Blob Storage.
- Abstract Your Service Calls: In your code, create an abstraction layer that sits between your application logic and the specific managed service API. This way, if you need to swap out the underlying service, you only have to change the implementation in one place.
Treat managed services as accelerators, not as your final destination. The ultimate leverage is knowing you can migrate a petabyte-scale data lake from one provider to another in under 30 days. That ability keeps you in the driver’s seat, free to adapt to changes in pricing, features, or your own strategy.
More Actionable Managed Service Strategies for 2025+
- Lock in Committed-Use Discounts First: The deepest discounts (up to 75% on AWS, 72% on Azure, 65% on GCP) are on managed offerings. Finance teams in 2025 treat these as the new “cloud capex”—locking 3-year commitments on managed databases immediately drops unit costs 50–60%.
- Adopt Managed AI/ML Services: Training models on self-managed GPU clusters costs 3–10× more than using Bedrock, Vertex AI, or Azure OpenAI Service. The 2025 Fortune-500 pattern is to use managed endpoints for 95% of inference, self-hosting only for top-secret IP models.
- Kill the ETL Graveyard: Replace 70% of custom Spark/Flink jobs with fully managed equivalents like Snowflake, BigQuery, or Databricks Serverless SQL. Real 2025 migrations show 8–15× faster time-to-insight and 60% lower TCO because you stop maintaining Kafka connectors forever.
Frequently Asked Questions
Let’s tackle some of the most common questions that come up when people start exploring managed cloud services. This should clear up some of the practical details around cost, control, and what it all means for your team.
What’s the Real Difference Between Managed Services and Outsourcing?
It’s easy to confuse these two, but they operate on completely different philosophies.
Traditional IT outsourcing is really about handing off a to-do list. You pay someone else to handle specific tasks, like patching servers or running nightly backups. It’s transactional and focuses on the activity.
Managed cloud services, on the other hand, are built around an Outcome-as-a-Service model. You’re not just buying someone’s time; you’re buying a guaranteed result. The conversation shifts from “Did you patch the server?” to “Did you deliver the 99.99% uptime we agreed to in the SLA?” This simple change completely aligns the provider’s incentives with your business goals.
How Will Managed Services Actually Affect My Budget?
The biggest change you’ll see is a shift from unpredictable capital expenses (CapEx) to a steady, predictable operational expense (OpEx). Instead of big, upfront costs for hardware and the staff to run it, you pay a recurring monthly or annual fee.
When you add up all the hidden costs of doing it yourself—like engineer time spent on late-night incident response, painful upgrades, and routine maintenance—the Total Cost of Ownership (TCO) is often much lower with a managed service.
We’ve seen teams discover that a self-managed system like Cassandra can end up costing 4–7 times more than a fully managed alternative like Amazon DynamoDB once all the labor is factored in.
Plus, you can get some serious discounts. By committing to multi-year contracts for services like Amazon RDS or Azure SQL, finance teams can lock in rates that are 50-60% lower than on-demand pricing. It’s like a new, more flexible form of “cloud capex.”
Are Managed Services Secure Enough for Regulated Industries?
Yes, and in many cases, they can actually strengthen your security and compliance. Think about the shared responsibility model: the big cloud providers like AWS, Azure, and GCP are on the hook for securing the foundational infrastructure.
They pour massive resources into maintaining certifications for standards like PCI-DSS, HIPAA, SOC 2, and ISO 27001. Your auditors will accept the provider’s paperwork for things like physical data center security and network infrastructure.
This frees up your team to focus solely on securing your application and the data inside it, not the entire stack from the concrete floor up. One team I know cut their audit prep time from six weeks down to just three days after moving their databases to a managed service. That’s a huge win.
Do I Give Up All Control by Using a Managed Service?
You’re trading one kind of control for another. You give up low-level, hands-on-keyboard control over server patching, but you gain high-level, strategic control to do things like scale your application globally in a matter of minutes.
The trick is to avoid getting painted into a corner with a single vendor. You can use these services as powerful accelerators without getting locked in permanently if you plan ahead.
Here’s how to stay in the driver’s seat:
- Embrace Open Data Formats: Structure your data pipelines around universal formats like Apache Parquet or Iceberg. This makes it much easier to move your data between platforms like Google BigQuery and Snowflake.
- Abstract the APIs: Instead of having your code call a provider’s API directly, build an internal interface that sits in between. If you ever need to swap out the underlying service, you only have to update your internal tool, not your entire application.
- Keep Your Exits Clear: Always have a well-documented and tested process for moving data between cloud storage systems (like from Amazon S3 to Azure Blob Storage).
This approach lets you get all the benefits of managed services while keeping your options open for the future.
Finding the right cloud partner is the first step to leveraging these powerful strategies. CloudConsultingFirms.com offers a data-driven guide to help you select the best AWS, Azure, or GCP consulting firm for your needs. Compare over 20 leading firms based on 2,400+ reviews, certifications, and real project outcomes. Find your ideal partner at https://cloudconsultingfirms.com.
Peter Korpak
Chief Analyst & Founder
Data-driven market researcher with 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse. Analyzed 200+ verified cloud projects (migrations, implementations, optimizations) to build Cloud Intel.
Connect on LinkedInContinue Reading
Managed Services
Data-driven rankings for leading managed service providers
The Complete Guide to Vetting and Hiring Managed Service Providers
Cut through the noise. This guide covers managed service provider costs, core benefits, and ranks the best platforms for vetting your next cloud MSP.
Stay ahead of cloud consulting
Quarterly rankings, pricing benchmarks, and new research — delivered to your inbox.
No spam. Unsubscribe anytime.